GPU vs CPU Performance for Matrix Multiplication
Introduction: Unleashing the Power of Parallelism in AI
The field of artificial intelligence has undergone a revolution in recent years, driven in large part by advancements in hardware and the innovative architectures they enable. Traditional models like Long Short-Term Memory networks (LSTMs) were once state-of-the-art, but their sequential nature limited their ability to leverage parallel processing. Enter Transformers: a game-changing architecture that has reshaped the AI landscape by fully embracing the power of parallel computation.
At the heart of this transformation is the GPU (Graphics Processing Unit). Originally designed for rendering photorealistic video games, GPUs have become indispensable for AI research and development. Their ability to execute thousands of simple operations simultaneously makes them ideal for tasks like matrix multiplication (and other linear algebra operations), an essential building block of neural networks. This distinction is exemplified in our interactive matrix multiplication demo below, where we compare parallel (GPU-powered) and non-parallel (CPU-based) computing. The results highlight why GPUs, & recently, TPU’s (Tensor Processing Units) are the cornerstone of modern AI.
Why LSTMs Hit a Wall
Long Short-Term Memory networks (LSTMs), while revolutionary for processing sequential data, face several fundamental limitations such as Sequential Processing Bottlenecks.
LSTMs are inherently sequential models. Each input token depends on the state produced by the previous token, making it impossible to process sequences in parallel. For example, in a 1000-token sequence, token #500 cannot be processed until all 499 previous tokens have been computed.
This sequential dependency results in slower training times and inefficiencies, particularly for long sequences. While modern GPUs excel at parallel computation, LSTMs cannot fully utilize this capability due to their architecture. The recursive nature of LSTMs means that every token must pass through the same network repeatedly, compounding these limitations.
Alternitivly, Modern Transformer architectures & GPU’s a have largely addressed these limitations through self-attention mechanisms and parallel processing capabilities, enabling efficient processing of much longer sequences.
Unlike CPUs, which have fewer but more complex cores, GPUs contain thousands of smaller, simpler cores optimized for parallel processing. This specialized architecture makes them exceptionally efficient at executing thousands of simple operations simultaneously, particularly for tasks like matrix multiplication and other linear algebra operations - the essential building blocks of neural networks.
How Transformers Overcame Sequential Processing Limitations
Transformers, introduced in the 2017 paper “Attention Is All You Need,” revolutionized sequence processing through two key innovations. Positional embeddings that encode token order, and the self-attention mechanism that calculates relationships between all tokens in parallel.
The parallel processing power of Transformers leverages two key computing concepts:
SIMD (Single Instruction Multiple Data) Architecture
Deep learning models process vast amounts of data using mathematical operations. At their core, these operations rely heavily on matrix multiplications to transform input data into meaningful representations. This aligns perfectly with modern GPU architectures optimized for SIMD operations, enabling attention calculations to execute in parallel across multiple tokens.
Embarrassingly Parallel Nature
Self-attention computations can be split into completely independent calculations, with multiple attention heads processing different relationship aspects with no dependencies. These highly optimized matrix operations on specialized hardware (TPUs, GPU Tensor Cores) enable parallelization in both training and inference.
This parallel architecture explains why Transformers scale so effectively to massive models and datasets compared to sequential architectures like LSTMs. The shift from O(n) sequential steps to parallel processing enabled training on unprecedented amounts of data, enabling new AI applications like modern Large Language Models (LLM’s).
Matrix Operations: The Core of AI Parallelism
The magic of Transformers lies in their utilisation of matrix operations—particularly within the self-attention mechanism. Tasks like calculating the relationships between queries, keys, and values in attention layers involve operations such as dot products between large matrices. GPUs excel at matrix math because:
- Massive Parallelism: GPUs have thousands of simple cores designed for executing parallel operations.
- High Memory Bandwidth: Modern GPUs can move data quickly between memory and processing units, a critical factor for large-scale computations.
- Vectorization: Operations on entire arrays (e.g., tensors) can be performed simultaneously, avoiding the inefficiency of loops.
Why GPUs Changed the Game
Before GPUs were repurposed for AI, CPUs were the primary drivers of computation. While CPUs are versatile, their limited core count and reliance on sequential processing made them ill-suited for the parallelism required by neural networks. GPUs, on the other hand, are optimized for embarrassingly parallel tasks, such as rendering 3D scenes and performing massive matrix multiplications. The introduction of CUDA in 2007 allowed researchers to unlock the full potential of GPUs for AI workloads, replacing clusters of CPUs with smaller, more powerful GPU setups.
Between 1990 and 2010, off-the-shelf CPUs became faster by a factor of approximately 5,000. As a result, nowadays it’s possible to run small deep learning models on your laptop, whereas this would have been intractable 25 years ago. But typical deep learning models used in computer vision or speech recognition require orders of magnitude more computational power than your laptop can deliver.
Throughout the 2000s, companies like NVIDIA and AMD invested billions of dollars in developing fast, massively parallel chips (graphical processing units, or GPUs) to power the graphics of increasingly photorealistic video games—cheap, single-purpose supercomputers designed to render complex 3D scenes on your screen in real time. This investment came to benefit the scientific community when, in 2007, NVIDIA launched CUDA, a programming interface for its line of GPUs. A small number of GPUs started replacing massive clusters of CPUs in various highly parallelizable applications, beginning with physics modeling. Deep neural networks, consisting mostly of many small matrix multiplications, are also highly parallelizable, and around 2011 some researchers began to write CUDA implementations of neural nets—Dan Ciresan and Alex Krizhevsky were among the first. - François Chollet 1
Scalability and Modern AI
Transformers are inherently scalable, and GPUs are their perfect companion. From the attention mechanism to feedforward layers, every step in the Transformer architecture benefits from parallelism. This synergy between hardware and architecture enabled the training of modern Large Language Models (LLMs) like GPT and BERT, which have billions of parameters. Without GPUs, training these models on massive datasets would take months or even years.
The Demo: Parallel Computing in Action
To truly appreciate the difference between parallel and sequential computing, check out the below matrix multiplication demo
- CPU (Non-Parallel): Processes matrix elements sequentially, with performance bottlenecks as input size grows.
- GPU (Parallel): Leverages thousands of cores to compute results simultaneously, demonstrating the massive speedup achieved through parallelism. For the purposes of this demo we are using four parraell procceses
This demonstration illustrates why GPUs are indispensable for deep learning, and why the Transformer arcitectue has replaced LSTMs as the foundation of modern AI.
Conclusion
The shift from LSTMs to Transformers exemplifies how embracing parallelism revolutionized AI. By leveraging GPU-optimized architectures and operations like matrix multiplication, researchers have dramatically increased the scale, speed, and efficiency of training neural networks. The Transformer arcitectures ability to process sequences in parallel not only solved the inefficiencies of sequential models but also enabled the creation of groundbreaking LLMs. This leap in computational efficiency has paved the way for the explosive growth of AI, transforming industries and inspiring innovations that were once thought impossible.
Artificial Neural Networks (ANNs), inspired by biological neurons, benefit immensely from GPUs because their core operations—primarily matrix multiplications—are inherently parallel. GPUs/TPUs are specifically designed for such workloads, with thousands of lightweight cores optimized for parallel matrix math and high memory bandwidth, making them ideal for the computational demands of AI.
Cuda Demo Code
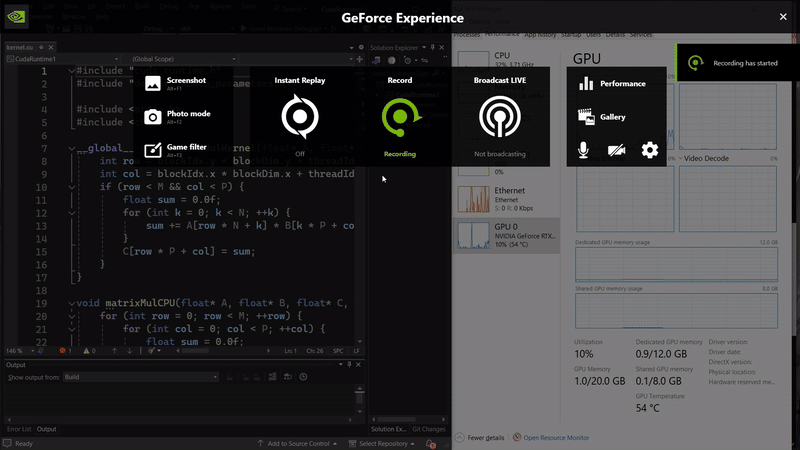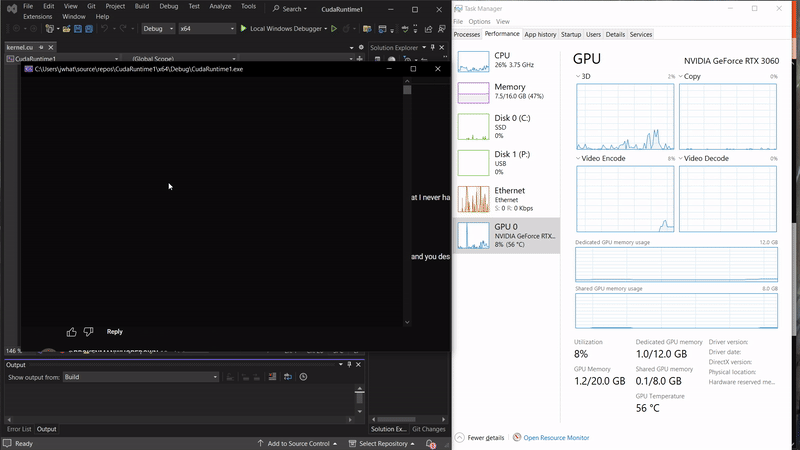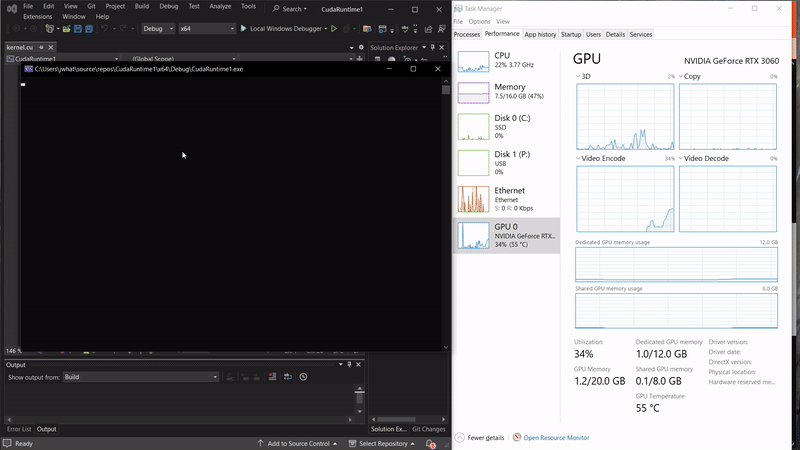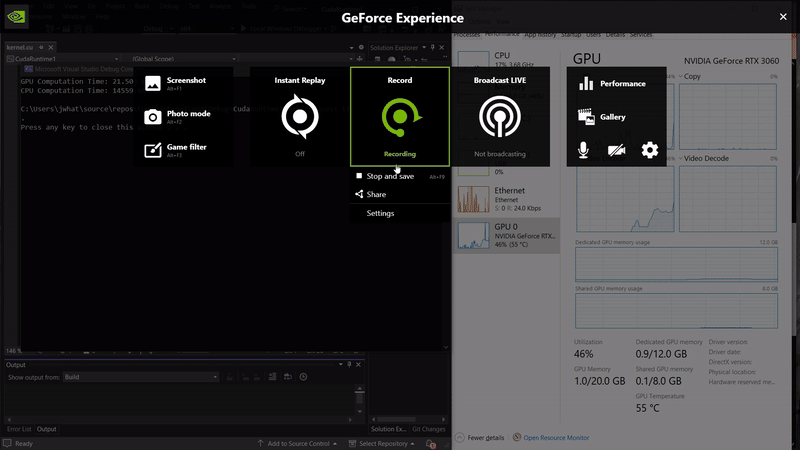
CPU Computation Time: 14559.604 ms
GPU Total Threads = (16 × 16) × [1024/16] × [1024/16] = 256 × 64 × 64 = 1,048,576
CPU Total Threads = 1 Single Thread
|
|
Supporting & additional reading resources
How do Graphics Cards Work? Exploring GPU Architecture - Branch Education Video
GPU Memory bandwidth requirements for machine learning - Adil Lheureux
CUDA Cores Vs Tensor Cores: Choosing The Right GPU For Machine Learning - AceCloud
Nvidia CUDA in 100 Seconds for parraell computations - Fireship Video
Transformers (how LLMs work) explained visually (Transformer mat mul) - 3Blue1Brown
SIMD Wiki - Wikipedia
What is SIMD? https://www.youtube.com/watch?v=YuUMCVX3UVE - Joshua Weinstein Video
Embarrassingly parallel computing - Wikipedia
-
Deep learning with Python 2nd Edition by François Chollet - Chapeter 1.3.1 Hardware Manning Books ↩︎